Editor’s Note: This presentation was given by Luanne Misquitta and Alessandro Negro at GraphConnect New York in October 2017.
Presentation Summary
Knowledge graphs are key to delivering
relevant search results to users, meeting the
four criteria for relevance, which include the query, the context, the user, and the business goal. Luanne Misquitta and Alessandro Negro describe the rise of knowledge graphs and their application in relevant search, highlighting a range of
use cases across industries before taking a deep dive into an
ecommerce use case they implemented for a customer.
In supporting relevant search, storing
multiple views in
Elasticsearch supports fast response for users while all data is stored in the knowledge graph. The talk covers key aspects of relevant search, including personalization and concept search and shows how using the
right tool for the right job led to a powerful solution for the customer that serves as a pattern for others to use.
Full Presentation: Knowledge Graph Search with Elasticsearch and Neo4j
This blog deals with how to deliver relevant search results using Neo4j and Elasticsearch:
Luanne Misquitta: The
Forrester Wave for Master Data Management said that “knowledge graphs provide contextual windows into master data domains and links between domains.”
![Learn how knowledge graphs connect data domains and more.]()
This is important because over the last few years there have been huge leaps from data to information to knowledge and then, finally, to automated reasoning. What’s key about knowledge graphs is that they play a fundamental role because they gather data from a variety of sources and they link them together in a very organic form. You’re also able to grow it, query it easily, maintain it easily and at the same time keep it relevant and up to date.
Use Cases for Knowledge Graphs
Knowledge graphs have been on the rise for the last couple of years across industries and
use cases.
![Discover where knowledge graphs are most widely used today.]()
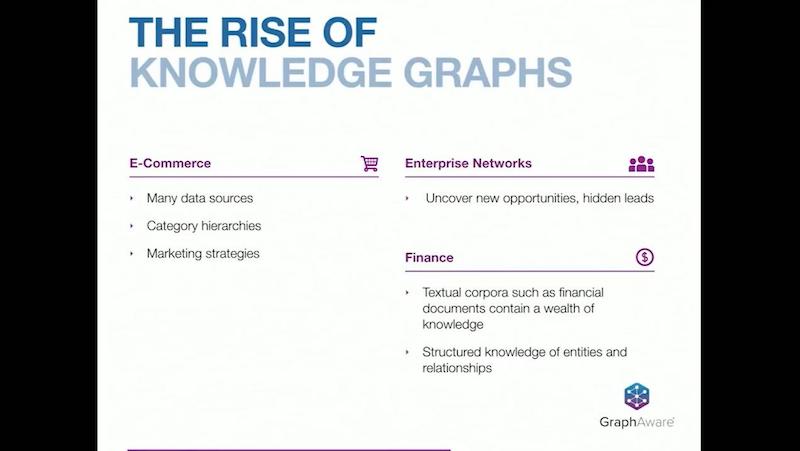
In
ecommerce, you have multiple data sources. It is one of the primary use cases for knowledge graphs. There are multiple category hierarchies; you almost never have a single hierarchy of products. You have products that are part of multiple different hierarchies.
This is quite a difficult problem to address if you don’t have a
graph database. You have the combination of not only products, categories, and data sources, but also marketing. Marketing strategies and promotions influence what you sell. The combination of these three elements merge well into the concept of a knowledge graph.
Enterprise networks connect partners, customers, employees, opportunities and providers. Knowledge graphs help you discover relationships between all these connected data sets and therefore discover new opportunities.
Finance has a textual corpora of financial documents, which contain a wealth of knowledge. There are many case studies such as the
ICIJ’s use of
Neo4j to analyze the
Panama Papers, an analysis that linked together more than 11 million documents. You end up with a very structured graph of entities, and how they are connected.
![Learn what industries are taking advantage of knowledge graphs.]() Health
Health is an important use case for knowledge graphs that has had many practical applications over the last few years. Knowledge graphs unify structured and unstructured data from multiple data sources and integrate them into a graph-based model with very dynamic ontologies where data is characterized and organized around people, places and events. This enables you to generate a lot of knowledge based on the co-occurrence of relationships and data.
Knowledge graphs are being used for uncovering patterns in disease progression, causal relations involving disease, symptoms and the treatment paths for numerous diseases. New relationships have been discovered that were previously unrecognized simply by putting all this data together and applying a context around where it happened, who was involved and other natural events that might have happened around this data.
Criminal investigation and intelligence is an area where numerous papers have been published recently about how knowledge graphs helped in investigating cases. One of the most familiar cases has been around the area of human trafficking. Knowledge graphs have helped, because it is a difficult field to track, and much of the information is obfuscated. Coded messages are posted on public forums and they form a pattern. Tools and techniques such as natural language processing (NLP) decode these messages, make sense of them, and apply context around them.
Another key part of the whole knowledge graph is that, especially with law enforcement, you really need to have traceability from your knowledge graph back to your source of information. Otherwise, none of this would hold up in a court of law. With the knowledge graph, you also maintain the traceability of your data from the source to the point at which it clearly provides you the information or the evidence that you need.
Data Sparsity
Now we’re going to talk about some of the problems you see around data sparsity.
![Learn about the problems surrounding data sparsity.]()
When you talk about collaborative filtering, one of the classic problems is a cold start. You cannot really recommend products or things to other people if you don’t even have other people in your graph or other purchases in your graph. This is commonly solved through things like tagging-based systems or trust networks. If you don’t have collaborative filtering, even content-based recommendation suffers a lot of problems due to missing data or wrong data. If you don’t have an enhanced graph to put all this data together, these are hard problems to solve.
With text search as well, with sparse data, you end up with user agnostic searches, and the world is moving away from anonymous agnostic searches to relevant context-oriented searches. Similarly, relevant search is a problem. So, these are some of the areas that we’ll touch upon in the later part of the presentation.
Knowledge Bases on Steroids
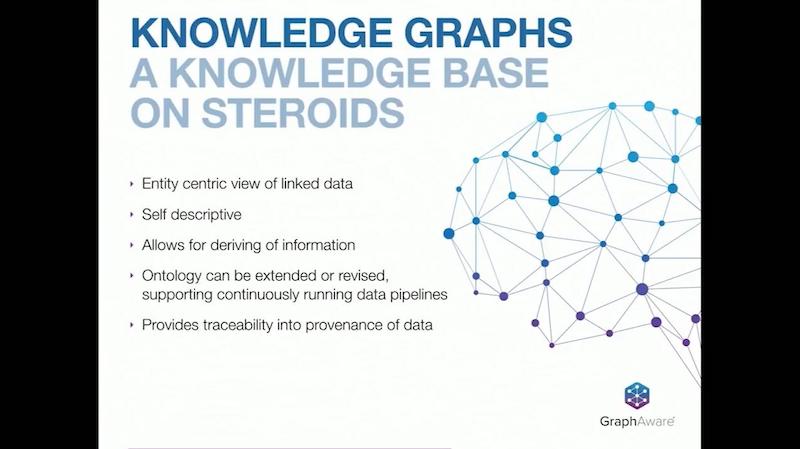
Knowledge graphs are what we used to know as knowledge bases but on steroids.
![Learn why knowledge graphs are really just a knowledge base on steroids.]()
Knowledge graphs provide you an entity-centric view of your linked data. They’re self descriptive, because the data that’s described is really described in your graph.
Therefore, you’re capable of growing this data in an organic fashion, enhancing it as you discover more and more facts about your data. You have an ontology that can be extended or revised, and it supports continuously running data pipelines. It’s not a static system that’s once built, remains that way forever; it grows as your domain expands.
Back to the law enforcement use case, it provides you traceability into the provenance of data, and this is important in many industries.
Knowledge Graphs as Data Convergence
A knowledge graph is really a convergence of data from a variety of places (see below).
![Discover how a knowledge graphs is a convergence of data.]()
You have data sources, which could come from all over the place, in all sorts of formats. You have external sources to enrich the data you have. You have user interaction, so as users play with your application or your domain, you learn more, you feed it back into the knowledge graph, and, therefore, you improve your knowledge graph. You have tools such as machine learning processes or NLP, which really, in the end, help you achieve your business goals.
Relevant Search
Alessandro Negro: Let’s consider a specific application of knowledge graphs – a specific use case that implements an advanced search engine that delivers relevant search capabilities to the end user.
![Learn how a knowledge graph provides relevant search capabilities.]()
Relevance here is the practice of improving search results, satisfying your data information needs in the context of a very specific user experience while combining or balancing how ranking impacts on a business’ certain needs.
Let’s walk through an implementation that combines graphs and, specifically, knowledge graphs, with Elasticsearch in order to deliver services to the end user.
You will see a real architecture and a concrete infrastructure where, combining both, it’s possible to deliver a high-level set of services to the end user. You will notice how knowledge graphs could help in this direction, not only because they solve issues related to data sparsity, but also because graphs represent a direct model for delivering these types of services to the end user.
Four Dimensions of Relevant Search
According to the definition stated before, relevance moves along four different dimensions. It revolves around four different elements: text, user, context and business goal.
![Check out the dimensions of relevant search.]()
First of all, a search has to satisfy an information need that is expressed by the user using a textual query.
So, in this context, information retrieval and natural language processing are key to provide search results that mostly satisfy the user intent expressed by the search query. But relevant search moves toward a more user-centric perspective of the search. That means that we can’t deliver the same result set to the same user even if they perform the same query.
In this way, user modeling and the recommendation engine could help to customize the result set according to the user profile or the user preferences. While on the other hand, context expresses the special conditions under which that specific search has been performed. Contextual information like location, time, or even the weather could be helpful to further refine the search results according to the needs of the user while he was performing the query.
Last but not least, the business goals drive the entire implementation, because a search exists only to satisfy a specific need of an organization in terms of revenue or in terms of a specific goal that it would like to achieve. Moreover, a relevant search has to store a lot of information related to search histories or feedback loops. And all this data has to be accessed in a way that shouldn’t affect the user experience in terms of performance that will impact response time or the quality of the results.
Knowledge Graphs for Relevant Search
Here is where knowledge graphs come in, because we will see how knowledge graphs represent the right approach in terms of information structure for providing relevant search.
![See how to structure information for relevant search.]()
In order to provide a relevant search, a search architecture has to handle high quality, high quantity of data that is heterogeneous in terms of schemas, sources,volume, and rate of generation. Furthermore, it has to be accessed as a unified data source. That means that it has to be normalized and accessed as a unified schema structure that satisfies all the informational and navigational requirements of a relevant search that we saw before.
Graphs are the right representation for all the issues related to relevant search including information extraction, recommendation engines, context representation, and even a rules engine for representing business goals.
Information extraction attempts to make the semantic structure in the text explicit, because we refer to text as unstructured data, but text has a lot of structure related to the grammar and the constraints of the language.
You can extract this information using natural language processing. From a document, you can extract the sentences. And for each sentence, you can extract a list of tags. And then, the relationships between these tags based on the types of dependencies, mentions or whatever else.
This is a connected set of data that can be easily stored in a graph. Once you store this data, you may easily extend the knowledge that you have about it, ingesting information from other knowledge graphs like
ConceptNet 5, which is an ontology structure that can be easily integrated in this basic set of information, adding new relationships to the graph.
On the other hand, recommendation engines are also built using user-item interactions that are easily stored in a graph. They can also be built using a content-based approach in which you will need to use informational extraction or a description or a list of features of the element you would like to recommend.
In both cases, the output of the process could be a list of similarities that could be easily stored in a graph as new relationships between items or between users. And then, you could use them to provide recommendations to the user that combine both approaches.
Context, by definition, is a multidimensional representation of a status or an event. Mainly, it is a multidimensional array. It is a tensor. A tensor is easily represented in a graph where you have an element that is one node and all the other indexes that refer to that element are other nodes that point to that specific node.
In this way, you can easily perform any sort of operation on the tensor, such as slicing, for example, or whatever else. Even easier is adding new indexes to this tensor – just adding a new node that points it to the element.
Finally, in order to apply a specific business goal, you have to implement a sort of rule engine. And even in this case, a graph could help you not only to store the rule itself, but also to enforce the rule in your system.
Use Case: Ecommerce Search Engine
Let’s consider a specific use case: a search engine for an ecommerce site.
![Check out this knowledge graph use case for ecommerce.]()
Every search application has its own requirements and its own dramatically specific set of constraints in terms of expectations from the search. In the case of a web search engine, you have millions of pages that are completely different from each other. And even the source of the knowledge cannot be trusted.
You might think ecommerce search is a simpler case, but it is not. It’s true that the set of documents is more controlled and in terms of numbers, reduced. But in an ecommerce site, the categories of navigation and the text search are the main “salespeople,” not just a way for searching for something. They also a way for promoting something, for shortening path between the need and the buyer. They are very important.
In terms of expectations, a search in an ecommerce site has a lot of things to do. But even more, in this case, you can gather data coming from multiple data sources: sellers, content providers, and marketers pushing a strategy or marketing campaign in the system like promotions, offers, or whatever else.
Also, you have to consider the users. You have to store user-item interactions and user feedback in order to customize the results provided to the user according to their history. And obviously, again, there are business constraints.
Here is a simplified example of a knowledge graph for an ecommerce site:
![Check out this simplified example of a knowledge graph for ecommerce.]()
The main element, in this case, is represented by the products. Here we have just three products: an iPhone, a case for the iPhone, and an earphone. For every product, we have some information like the list of features that describe that product. But obviously this list of features will change according to the type of the product, so it will be different for a TV, a pair of shoes and so on.
Starting from this information, it’s easy to process the textual description and the list of tags. Once we have the tags, we are able to ingest data from ConceptNet 5 and know that a smartphone is a personal device.We will see how this is valuable information later on for providing relevant search. But apart from the data that is common for this type of application, we also analyze our data and create new relationships between items.
This is how relationships like “usually bought together” come into play. It’s also possible to manually add relationships, like the relationship between a phone and a case. In this way, you are augmenting the amount of knowledge that you have step by step and using all this knowledge during the search and during catalog navigation.
Infrastructure for the Knowledge Graph
With all these ideas in mind, we designed this infrastructure for one of our customers:
![Check out GraphAware's knowledge graph infrastructure using Neo4j and Elasticsearch.]()
The knowledge graph is the main source of truth in this infrastructure, and several other sources feed the knowledge graph. A machine-learning platform processes the graph continuously and extracts insights from the knowledge graph and then stores the insights back into the knowledge graph.
Later we’ll discuss how the integration with Elasticsearch allows us to export multiple views with multiple scopes so that knowledge graph queries do not impact the front end too much. We use Elasticsearch as a sort of cache and also a powerful search engine on top of our knowledge graph.
Data Flow for the Knowledge Graph
For the data flow, we designed an asynchronous data ingestion process where we have multiple data sources pushing data in multiple queues. A microservice infrastructure reacts to these events, processes them, and stores this intermediate data in one queue that then is processed by a single Neo4j Writer element that reads the data and stores it in the graph.
This avoids any issues in terms of concurrency, and it also enables us to easily implement a priority-based mechanism that allows us to assign different priorities to an element.
Storing Multiple Views in Elasticsearch
In order to store multiple views in Elasticsearch, we created an event-based notification system that is highly customizable and capable of pushing several types of events. The Elasticsearch Writer reacts to these events, reads data from the knowledge graph and creates new documents or updates existing documents in Elasticsearch.
The Role of Neo4j
Neo4j is the core of this infrastructure because it stores the knowledge graph, which is the only source of truth. There is no other data somewhere else. All the data that we would like to process is here. It all converges here in this knowledge graph.
![Learn about Neo4j's role in the knowledge graph.]()
Neo4j is a valuable tool because it allows you to store several types of data: users, products, details about products and whatever else. It also provides an easy-to-query mechanism and an easy-to-navigate system for easily accessing this data.
More than that, in the early stage of the relevant search implementation, it can help the relevance engineer to identify the most interesting feature in the knowledge graph that’s useful for the implementation of the related search in the system.
Moreover, once all the data is in the graph, it goes through a process of extension that includes three different operations: cleaning, existing data augmentation and data merging. Because multiple sources can express the same concept in different ways, data merging is also important.
Machine Learning for Memory-Intensive Processes
Some of these processes can be accomplished in Neo4j itself with some plugins or with
Cypher queries. Others need to be externalized, because they are intensive in terms of computational needs and memory requirements.
We created a machine learning platform (see below) that, thanks to the
Neo4j Spark connector, allows us to extract data from Neo4j, process it using natural language processing or even recommendation model building, and then store this new data in Neo4j, which will be useful later on for providing advanced features for the relevant search.
![Discover more about enternalise intense processes.]()
Elasticsearch for Fast Results
We are trying to use the right tool for the right job. We use Neo4j for storing the knowledge graph and it is perhaps the most valuable tool for doing this, but obviously, in terms of textual search, it could be an issue if you want to perform more advanced textual search in Neo4j. We added Elasticsearch on top of Neo4j in order to provide fast, reliable, and easy-to-tune textual search.
![Learn more about Elasticsearch roles in the knowledge graph.]()
We store multiple views of the same data set in Elasticsearch for solving several scopes and for serving several functionalities that are faceting. Faceting means any sort of aggregation of the result set that you want to have. You can serve a product details page or provide product variants aggregation. With Elasticsearch, you can also provide auto-completion or suggestions.
Elasticsearch is not a database, and we don’t want to use it as a database. It is just a search engine for data from Neo4j in this use case and is a valuable tool for textual search.
Relevant Search on Top of Knowledge Graph
Now let’s explore using Elasticsearch to provide relevant search on top of the knowledge graph that we built using the infrastructure covered earlier.
What Is a Signal?
In terms of relevant search, a signal is any component of a relevance-scoring calculation corresponding to meaningful and measurable information. At its simplest, it is just a field in a document in Elasticsearch.
The complicated part is how you design this field, what you put inside it and how you can extract from the knowledge graph and store data in Elasticsearch that really matters.
There are two main techniques for controlling relevancy (see below). The first one is signal modeling. It is how you design the list of fields that compose your documents in order to react to some textual query. And the other one is the ranking function, or the ranking functions, that are how you compose several signals and assign each of them a specific weight in order to obtain the final score and the rank of the results.
![Learn more about crafting signals in the knowledge graph.]()
You always have to balance precision and recall where, in this context, precision is the percentage of documents in the result set that are relevant and recall is the percentage of relevant documents in the result set.
It’s a complicated topic, but to simplify it, if you return all the documents to the user, you have a recall of 100%, because you have all the relevant documents in the result set. With a recall of 100%, you have a very low degree of precision. And even in this case, you can have multiple sources in terms of data from the knowledge graph that you can use for modeling your signal.
Personalizing Search
Let me give you a couple of examples. The first approach is personalizing search.
![Learn more about personalizing search with a knowledge graph.]()
Here, we include users as a new source of information so we can provide a customized result set. We would like to customize the result set according to the user profile or the user preferences.
We have two different approaches. The first one is a profile-based approach where we create a user profile that could be created manually by the user by filling out a form, or automatically, inferring user preferences from past searches.
The second approach is behavioral based. In this case, it’s more related to a recommendation engine that analyzes the user-item interaction in order to make explicit the relationship among users and items.
Once you have a user profile or behavioral information, you have to tie this information to the query. And you can do this in three different ways: at query time, changing the query according to the recommendation that you would like to make; at index time, changing the documents according to the recommendation that you would like to make; or using a combined approach.
For example, if you would like to customize the results for the user at query time, you have to change your query, specifying the list of products that the user may be interested in. In this way, you could easily boost the results if the results set includes some of the products that the user is known to be interested in. On the other hand, at index time, you would have to store a list of users that may be interested in each product. And then you can easily boost results that specifically match in that case.
Concept Search
Another interesting extension of the classical search is the concept search. In this case, we move from searching for strings to searching for things.
![Discover how a knowledge graph assists with concept search capabilities.]()
The user could use different words for expressing the same concept. This can be an issue in a classical text search environment where you have to match the specific word that appears in the text. Using the techniques that we described before in terms of data enrichment, you can easily extend the knowledge that you have about each word. You can easily store those words in Elasticsearch and react to the user’s query even if he is not using the terms that are on the page.
There are different approaches to enriching this information. You can manually, or even automatically, add a list of tags that could be helpful in terms of the describing the content. You can write a list of synonyms. For example, for TV, you can have synonyms like T.V., or television, or whatever else. And in this way, even if the text says TV, you can easily provide results if the user writes television, for example.
There is a more advanced approach in which you use machine learning tools for augmenting the knowledge. You can use a simple co-occurrence as well as
Latent Dirichlet Allocation. That means clustering your document set, and finding the set of the words that better describes that specific cluster and all the documents in that cluster.
Combining Neo4j and Elasticsearch: Two Approaches
Here are two different approaches that we tried when integrating Neo4j and Elasticsearch.
On the left side below is the first approach, which has two elements: the documents in Elasticsearch and the graph database.
![Discover combined search approaches for the knowledge graph.]()
In this approach, when a user performed a query, it goes through two different phases. The first one is the classical textual search query that is performed entirely on Elasticsearch.
The first result set is then manipulated by accessing the graph, and boosting the results according to whatever rule you’d like to use. This approach could work, but in terms of performance, could suffer a little bit when you have to do complex boosting operations.
As a result, we moved to the second approach (see above right), in which there is a tighter connection between Elasticsearch and the knowledge graph. Using this approach, as discussed earlier, the knowledge graph is used for exporting multiple views into Elasticsearch.
Part of the work is done at index time. When the user performs a query, the query itself goes through a first stage that is an enrichment. Accessing the graph, we can change the query, and then we perform the query against Elasticsearch. This appears to be a more performant approach, because this operation itself is not related to every single element in the graph, but is narrowed based on the context or on the user, so it is very fast.
We can use Elasticsearch for what is supposed to be just textual search. But at that point, we already have a very complex query that is created using the graph. And even the indexes are really changed according to the graph’s structure.
Conclusion
Knowledge graphs are very important because they use graphs for representing complex knowledge. Knowledge graphs use an easy-to-query model that allows us to gather data from several sources. That means we can store users, user-item interactions, and whatever else we want. We can further extend important data later on or change our knowledge graph by adding new information.
On top of this, we can implement a search engine like Elasticsearch, which is fast, reliable, and easy-to-tune and which provides other interesting features, such as faceting and auto-completion.
By combining Neo4j and Elasticsearch, you can deliver a high level set of services to the end user. The takeaway is to use the right tool for the right job. You can use a graph for representing complex knowledge and a simple tool like Elasticsearch to provide textual search capability and advanced search capability to the end user.

 Editor’s Note: GraphAware is a Silver sponsor of GraphConnect San Francisco. Register for GraphConnect to meet Michal and other sponsors in person.
Editor’s Note: GraphAware is a Silver sponsor of GraphConnect San Francisco. Register for GraphConnect to meet Michal and other sponsors in person.